Subgradient optimization: Difference between revisions
No edit summary |
No edit summary |
||
| Line 1: | Line 1: | ||
Author Name: Aaron Anderson (ChE 345 Spring 2015) | Author Name: Aaron Anderson (ChE 345 Spring 2015) <br/> | ||
Steward: Dajun Yue and Fengqi You | Steward: Dajun Yue and Fengqi You | ||
A convex nondifferentiable function (blue) with red "subtangent" lines generalizing the derivative at the nondifferentiable point ''x''<sub>0</sub>. | [[File:Subderivative_illustration.png|right|thumb|A convex nondifferentiable function (blue) with red "subtangent" lines generalizing the derivative at the nondifferentiable point ''x''<sub>0</sub>.]] | ||
'''Subgradient Optimization''' (or '''Subgradient Method''') is an iterative algorithm for minimizing convex functions, used predominantly in Nondifferentiable optimization for functions that are convex but nondifferentiable. It is often slower than Newton's Method when applied to convex differentiable functions, but can be used on convex nondifferentiable functions where Newton's Method will not converge. It was first developed by Naum Z. Shor in the Soviet Union in the 1960's. | |||
'''Subgradient Optimization''' (or '''Subgradient Method''') is an iterative algorithm for minimizing convex functions, used predominantly in Nondifferentiable optimization for functions that are convex but nondifferentiable. It is often slower than Newton's Method when applied to convex differentiable functions, but can be used on convex nondifferentiable functions where Newton's Method will not converge. It was first developed by Naum Z. Shor in the Soviet Union in the 1960's | |||
==Introduction== | |||
The '''Subgradient''' (related to Subderivative and Subdifferential) of a function is a way of generalizing or approximating the derivative of a convex function at nondifferentiable points. The definition of a subgradient is as follows: <math>g</math> is a subgradient of <math>f</math> at <math>x</math> if, for all <math>y</math>, the following is true: <br/> | |||
[[File:Subgradient.png|200px|center]] | |||
An example of the subgradient of a nondifferentiable convex function <math>f</math> can be seen below: | |||
[[File:Subgradient2.png|600px|center]] | |||
Where <math>g_1</math> is a subgradient at point <math>x_1</math> and <math>g_2</math> and <math>g_3</math> are subgradients at point <math>x_2</math>. Notice that when the function is differentiable, such as at point <math>x_1</math>, the subgradient, <math>g_1</math>, just becomes the gradient to the function. Other important factors of the subgradient to note are that the subgradient gives a linear global underestimator of <math>f</math> and if <math>f</math> is convex, then there is at least one subgradient at every point in its domain. The set of all subgradients at a certain point is called the subdifferential, and is written as <math>\partial f(x_0)</math> at point <math>x_0</math>. | |||
An algorithm flowchart is provided below for the subgradient method: | ==The Subgradient Method== | ||
Suppose <math>f:\mathbb{R}^n \to \mathbb{R}</math> is a convex function with domain <math>\mathbb{R}^n</math>. To minimize <math>f</math> the subgradient method uses the iteration: <br/> | |||
[[File:Submethod1.png|center]] | |||
Where <math>k</math> is the number of iterations, <math>x^{(k)}</math> is the <math>k</math>th iterate, <math>g^{(x)}</math> is ''any'' subgradient at <math>x^{(k)}</math>, and <math>\alpha_k</math><math>(> 0)</math> is the <math>k</math>th step size. Thus, at each iteration of the subgradient method, we take a step in the direction of a negative subgradient. As explained above, when <math>f</math> is differentiable, <math>g^{(k)}</math> simply reduces to <math>\nabla</math><math>f(x^{(k)})</math>. It is also important to note that the subgradient method is not a descent method in that the new iterate is not always the best iterate. Thus we need some way to keep track of the best solution found so far, ''i.e.'' the one with the smallest function value. We can do this by, after each step, setting <br/> | |||
[[File:submethod2.png|200px|center]] | |||
and setting <math>i_{\text{best}}^{(k)} = k</math> if <math>x^{(k)}</math> is the best (smallest) point found so far. Thus we have: | |||
[[File:submethod3.png|237px|center]] | |||
which gives the best objective value found in <math>k</math> iterations. Since this value is decreasing, it has a limit (which can be <math>-\infty</math>). <br/> | |||
<br/> | |||
An algorithm flowchart is provided below for the subgradient method: <br/> | |||
[[File:SMFlowsheet.png|400px|center]] | |||
=== Step size === | ===Step size=== | ||
Several different step size rules can be used: | Several different step size rules can be used: | ||
*'''Constant step size''': <math>\alpha_k = h</math> independent of <math>k</math>. | |||
* '''Constant step size''': | *'''Constant step length''': [[File:stepsize1.png]] This means that [[File:stepsize2.png]] | ||
* '''Constant step length''': | *'''Square summable but not summable''': These step sizes satisfy | ||
* '''Square summable but not summable''': These step sizes satisfy | :[[File:stepsize3.png]] | ||
:One typical example is [[File:stepsize4.png]] where <math>a>0</math> and <math>b\ge0</math>. | |||
: | *'''Nonsummable diminishing''': These step sizes satisfy | ||
: One typical example is | :[[File:stepsize5.png]] | ||
:One typical example is [[File:stepsize6.png]] where <math>a>0</math>. | |||
* '''Nonsummable diminishing''': These step sizes satisfy | |||
: | |||
: One typical example is | |||
An important thing to note is that for all four of the rules given here, the step sizes are determined "off-line", or before the method is iterated. Thus the step sizes do not depend on preceding iterations. This "off-line" property of subgradient methods differs from the "on-line" step size rules used for descent methods for differentiable functions where the step sizes do depend on preceding iterations. | An important thing to note is that for all four of the rules given here, the step sizes are determined "off-line", or before the method is iterated. Thus the step sizes do not depend on preceding iterations. This "off-line" property of subgradient methods differs from the "on-line" step size rules used for descent methods for differentiable functions where the step sizes do depend on preceding iterations. | ||
=== Convergence Results === | ===Convergence Results=== | ||
There are different results on convergence for the subgradient method depending on the different step size rules applied. For constant step size rules and constant step length rules the subgradient method is guaranteed to converge within some range of the optimal value. Thus: | There are different results on convergence for the subgradient method depending on the different step size rules applied. | ||
For constant step size rules and constant step length rules the subgradient method is guaranteed to converge within some range of the optimal value. Thus: | |||
where | [[File:convergence1.png|center]] | ||
where <math>f^{*}</math> is the optimal solution to the problem and <math>\epsilon</math> is the aforementioned range of convergence. This means that the subgradient method finds a point within <math>\epsilon</math> of the optimal solution <math>f^{*}</math>. <math>\epsilon</math> is number that is a function of the step size parameter <math>h</math>, and as <math>h</math> decreases the range of convergence <math>\epsilon</math> also decreases, ''i.e.'' the solution of the subgradient method gets closer to <math>f^{*}</math> with a smaller step size parameter <math>h</math>. | |||
For the diminishing step size rule and the square summable but not summable rule, the algorithm is guaranteed to converge to the optimal value or [[File:convergence2.png]] When the function <math>f</math> is differentiable the subgradient method with constant step size yields convergence to the optimal value, provided the parameter <math>h</math> is small enough. | |||
Overall, all four step size rules can be used to get good convergence, so it is important to try different values for | ==Example: Piecewise linear minimization== | ||
Suppose we wanted to minimize the following piecewise linear convex function using the subgradient method: <br/> | |||
[[File:Example1.png|center]] | |||
Since this is a linear programming problem finding a subgradient is simple: given <math>x</math> we can find an index <math>j</math> for which: | |||
[[File:Example2.png|center]] | |||
The subgradient in this case is <math>g=a_j</math>. Thus the iterative update is then: | |||
[[File:Example3.png|center]] | |||
Where <math>j</math> is chosen such to satisfy [[File:Example4.png]] | |||
In order to apply the subgradient method to this problem all that is needed is some way to calculate [[File:Example5.png]] and the ability to carry out the iterative update. Even if the problem is dense and very large (where standard linear programming might fail), if there is some efficient way to calculate <math>f</math> then the subgradient method is a reasonable choice for algorithm. | |||
Consider a problem with <math>n=10</math> variables and <math>m=100</math> terms and with data <math>a_i</math> and <math>b_i</math> generated from a normal distribution. We will consider all four of the step size rules mentioned above and will plot <math>\epsilon</math> or the difference between the optimal solution and the subgradient solution as a function of <math>k</math>, the nuber of iterations. <br/> | |||
For the constant step size rule [[File:Example6.png]] for several values of <math>h</math> the following plot was obtained: <br/> | |||
[[File:Example7.png]] <br/> | |||
For the constant step length rule [[File:Example8.png]] for several values of <math>h</math> the following plot was obtained: <br/> | |||
[[File:Example9.png]] <br/> | |||
The above figures reveal a trade-off: a larger step size parameter <math>h</math> gives a faster convergence but in the end gives a larger range of suboptimality so it is important to determine an <math>h</math> that will converge close to the optimal solution without taking a very large number of iterations. <br/> | |||
For the subgradient method using diminishing step size rules, both the nonsummable diminishing step size rule [[File:Example10.png]] (blue) and the square summable but not summable step size rule [[File:Example11.png]] (red) are plotted below for convergence: <br/> | |||
[[File:Example12.png]] <br/> | |||
This figure illustrates that both the nonsummable diminishing step size rule and the square summable but not summable step size rule show relatively fast and good convergence. The square summable but not summable step size rule shows less variation than the nonsummable diminishing step size rule but both show similar speed and convergence. <br/> | |||
Overall, all four step size rules can be used to get good convergence, so it is important to try different values for <math>h</math> in the constant step size and length rules and different formulas for the nonsummable diminishing step size rule and the square summable but not summable step size rule in order to get good convergence in the smallest amount of iterations possible. | |||
== Conclusion == | ==Conclusion== | ||
The subgradient method is a very simple algorithm for minimizing convex nondifferentiable functions where newton's method and simple linear programming will not work. While the subgradient method has a disadvantage in that it can be much slower than interior-point methods such as Newton's method, it as the advantage of the memory requirement being often times much smaller than those of an interior-point or Newton method, which means it can be used for extremely large problems for which interior-point or Newton methods cannot be used. Morever, by combining the subgradient method with primal or dual decomposition techniques, it is sometimes possible to develop a simple distributed algorithm for a problem. The subgradient method is therefor an important method to know about for solving convex minimization problems that are nondifferentiable or very large. | The subgradient method is a very simple algorithm for minimizing convex nondifferentiable functions where newton's method and simple linear programming will not work. While the subgradient method has a disadvantage in that it can be much slower than interior-point methods such as Newton's method, it as the advantage of the memory requirement being often times much smaller than those of an interior-point or Newton method, which means it can be used for extremely large problems for which interior-point or Newton methods cannot be used. Morever, by combining the subgradient method with primal or dual decomposition techniques, it is sometimes possible to develop a simple distributed algorithm for a problem. The subgradient method is therefor an important method to know about for solving convex minimization problems that are nondifferentiable or very large. | ||
== References == | ==References== | ||
1. Akgul, M. "Topics in Relaxation and Ellipsoidal Methods", volume 97 of Research Notes in Mathematics. Pitman, 1984. | 1. Akgul, M. "Topics in Relaxation and Ellipsoidal Methods", volume 97 of Research Notes in Mathematics. Pitman, 1984. <br/> | ||
2. Bazaraa, M. S., Sherali, H. D. "On the choice of step size in subgradient optimization." European Journal of Operational Research 7.4, 1981 | 2. Bazaraa, M. S., Sherali, H. D. "On the choice of step size in subgradient optimization." European Journal of Operational Research 7.4, 1981 <br/> | ||
3. Bertsekas, D. P. "Nonlinear Programming", (2nd edition), Athena Scientific, Belmont, MA, 1999. | 3. Bertsekas, D. P. "Nonlinear Programming", (2nd edition), Athena Scientific, Belmont, MA, 1999. <br/> | ||
4. Goffin, J. L. "On convergence rates of subgradient optimization methods." Mathematical Programming 13.1, 1977. | 4. Goffin, J. L. "On convergence rates of subgradient optimization methods." Mathematical Programming 13.1, 1977. <br/> | ||
5. Shor, N. Z. "Minimization Methods for Non-differentiable Functions". Springer Series in Computational Mathematics. Springer, 1985. | 5. Shor, N. Z. "Minimization Methods for Non-differentiable Functions". Springer Series in Computational Mathematics. Springer, 1985. <br/> | ||
6. Shor, N. Z. "Nondifferentiable Optimization and Polynomial Problems". Nonconvex Optimization and its Applications. Kluwer, 1998. | 6. Shor, N. Z. "Nondifferentiable Optimization and Polynomial Problems". Nonconvex Optimization and its Applications. Kluwer, 1998. <br/> | ||
Revision as of 10:52, 1 April 2022
Author Name: Aaron Anderson (ChE 345 Spring 2015)
Steward: Dajun Yue and Fengqi You

Subgradient Optimization (or Subgradient Method) is an iterative algorithm for minimizing convex functions, used predominantly in Nondifferentiable optimization for functions that are convex but nondifferentiable. It is often slower than Newton's Method when applied to convex differentiable functions, but can be used on convex nondifferentiable functions where Newton's Method will not converge. It was first developed by Naum Z. Shor in the Soviet Union in the 1960's.
Introduction
The Subgradient (related to Subderivative and Subdifferential) of a function is a way of generalizing or approximating the derivative of a convex function at nondifferentiable points. The definition of a subgradient is as follows: is a subgradient of at if, for all , the following is true:





An example of the subgradient of a nondifferentiable convex function can be seen below:

Where is a subgradient at point and and are subgradients at point . Notice that when the function is differentiable, such as at point , the subgradient, , just becomes the gradient to the function. Other important factors of the subgradient to note are that the subgradient gives a linear global underestimator of and if is convex, then there is at least one subgradient at every point in its domain. The set of all subgradients at a certain point is called the subdifferential, and is written as at point .







The Subgradient Method
Suppose is a convex function with domain . To minimize the subgradient method uses the iteration:



Where is the number of iterations, is the th iterate, is any subgradient at , and is the th step size. Thus, at each iteration of the subgradient method, we take a step in the direction of a negative subgradient. As explained above, when is differentiable, simply reduces to . It is also important to note that the subgradient method is not a descent method in that the new iterate is not always the best iterate. Thus we need some way to keep track of the best solution found so far, i.e. the one with the smallest function value. We can do this by, after each step, setting









and setting if is the best (smallest) point found so far. Thus we have:


which gives the best objective value found in iterations. Since this value is decreasing, it has a limit (which can be ).
An algorithm flowchart is provided below for the subgradient method:


Step size
Several different step size rules can be used:
- Constant step size: independent of .
- Constant step length:
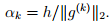 This means that
This means that 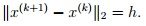
- Square summable but not summable: These step sizes satisfy

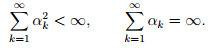
- One typical example is
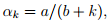 where and .
where and .


- Nonsummable diminishing: These step sizes satisfy
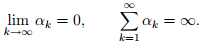
- One typical example is
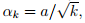 where .
where .
An important thing to note is that for all four of the rules given here, the step sizes are determined "off-line", or before the method is iterated. Thus the step sizes do not depend on preceding iterations. This "off-line" property of subgradient methods differs from the "on-line" step size rules used for descent methods for differentiable functions where the step sizes do depend on preceding iterations.
Convergence Results
There are different results on convergence for the subgradient method depending on the different step size rules applied. For constant step size rules and constant step length rules the subgradient method is guaranteed to converge within some range of the optimal value. Thus:

where is the optimal solution to the problem and is the aforementioned range of convergence. This means that the subgradient method finds a point within of the optimal solution . is number that is a function of the step size parameter , and as decreases the range of convergence also decreases, i.e. the solution of the subgradient method gets closer to with a smaller step size parameter .
For the diminishing step size rule and the square summable but not summable rule, the algorithm is guaranteed to converge to the optimal value or ![]() When the function is differentiable the subgradient method with constant step size yields convergence to the optimal value, provided the parameter is small enough.
When the function is differentiable the subgradient method with constant step size yields convergence to the optimal value, provided the parameter is small enough.



Example: Piecewise linear minimization
Suppose we wanted to minimize the following piecewise linear convex function using the subgradient method:

Since this is a linear programming problem finding a subgradient is simple: given we can find an index for which:


The subgradient in this case is . Thus the iterative update is then:


Where is chosen such to satisfy  In order to apply the subgradient method to this problem all that is needed is some way to calculate
In order to apply the subgradient method to this problem all that is needed is some way to calculate ![]() and the ability to carry out the iterative update. Even if the problem is dense and very large (where standard linear programming might fail), if there is some efficient way to calculate then the subgradient method is a reasonable choice for algorithm.
Consider a problem with variables and terms and with data and generated from a normal distribution. We will consider all four of the step size rules mentioned above and will plot or the difference between the optimal solution and the subgradient solution as a function of , the nuber of iterations.
and the ability to carry out the iterative update. Even if the problem is dense and very large (where standard linear programming might fail), if there is some efficient way to calculate then the subgradient method is a reasonable choice for algorithm.
Consider a problem with variables and terms and with data and generated from a normal distribution. We will consider all four of the step size rules mentioned above and will plot or the difference between the optimal solution and the subgradient solution as a function of , the nuber of iterations.
For the constant step size rule File:Example6.png for several values of the following plot was obtained:

For the constant step length rule ![]() for several values of the following plot was obtained:
for several values of the following plot was obtained:

The above figures reveal a trade-off: a larger step size parameter gives a faster convergence but in the end gives a larger range of suboptimality so it is important to determine an that will converge close to the optimal solution without taking a very large number of iterations.
For the subgradient method using diminishing step size rules, both the nonsummable diminishing step size rule ![]() (blue) and the square summable but not summable step size rule
(blue) and the square summable but not summable step size rule ![]() (red) are plotted below for convergence:
(red) are plotted below for convergence:

This figure illustrates that both the nonsummable diminishing step size rule and the square summable but not summable step size rule show relatively fast and good convergence. The square summable but not summable step size rule shows less variation than the nonsummable diminishing step size rule but both show similar speed and convergence.
Overall, all four step size rules can be used to get good convergence, so it is important to try different values for in the constant step size and length rules and different formulas for the nonsummable diminishing step size rule and the square summable but not summable step size rule in order to get good convergence in the smallest amount of iterations possible.




{kind=link}
Conclusion
The subgradient method is a very simple algorithm for minimizing convex nondifferentiable functions where newton's method and simple linear programming will not work. While the subgradient method has a disadvantage in that it can be much slower than interior-point methods such as Newton's method, it as the advantage of the memory requirement being often times much smaller than those of an interior-point or Newton method, which means it can be used for extremely large problems for which interior-point or Newton methods cannot be used. Morever, by combining the subgradient method with primal or dual decomposition techniques, it is sometimes possible to develop a simple distributed algorithm for a problem. The subgradient method is therefor an important method to know about for solving convex minimization problems that are nondifferentiable or very large.
References
1. Akgul, M. "Topics in Relaxation and Ellipsoidal Methods", volume 97 of Research Notes in Mathematics. Pitman, 1984.
2. Bazaraa, M. S., Sherali, H. D. "On the choice of step size in subgradient optimization." European Journal of Operational Research 7.4, 1981
3. Bertsekas, D. P. "Nonlinear Programming", (2nd edition), Athena Scientific, Belmont, MA, 1999.
4. Goffin, J. L. "On convergence rates of subgradient optimization methods." Mathematical Programming 13.1, 1977.
5. Shor, N. Z. "Minimization Methods for Non-differentiable Functions". Springer Series in Computational Mathematics. Springer, 1985.
6. Shor, N. Z. "Nondifferentiable Optimization and Polynomial Problems". Nonconvex Optimization and its Applications. Kluwer, 1998.